Qwen3-Next: Alibaba’s 80B-Parameter Breakthrough in Open-Source AI
Experience the next generation of efficiency and scale with Qwen3-Next — Alibaba’s open-source LLM featuring 80B parameters, 3B active per inference, and a record 262K context window. Faster, smarter, and built for complex real-world tasks.

Qwen3-Next: Alibaba’s Next-Generation Open-Source LLM
Qwen3-Next is Alibaba’s groundbreaking 80B-parameter language model that activates only 3B per inference, delivering massive efficiency gains without sacrificing performance. Open-sourced under Apache 2.0, it’s freely available for research and enterprise deployment.
Extreme Efficiency with Sparse Activation
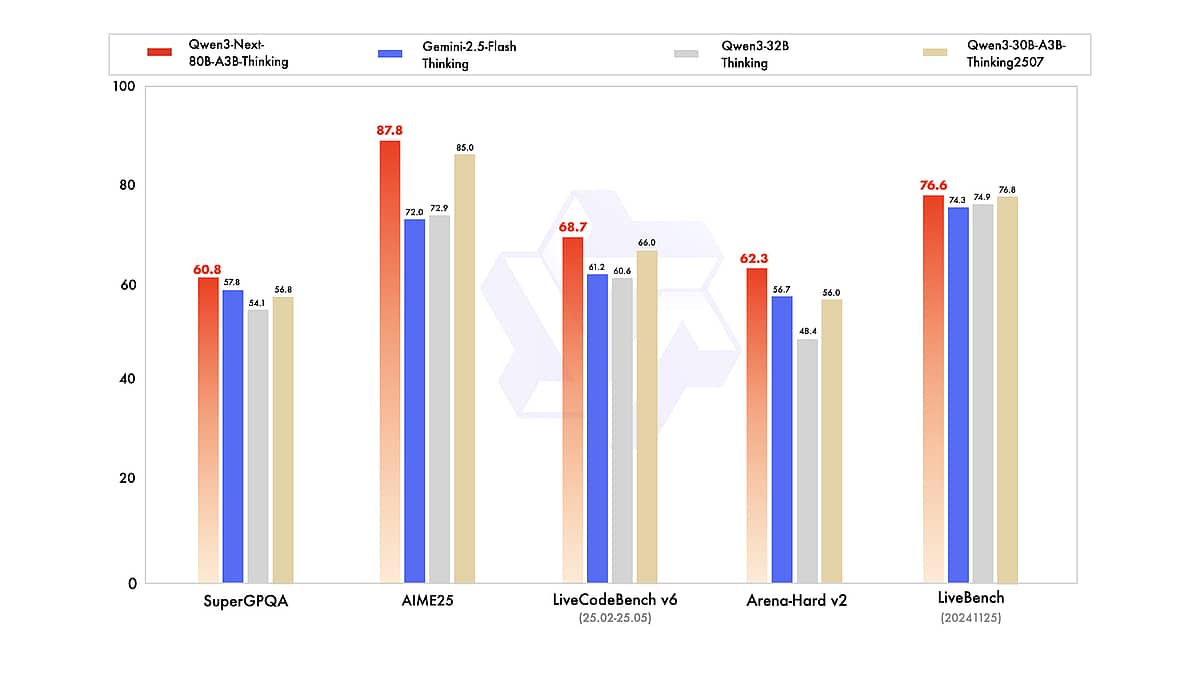
Qwen3-Next slashes compute costs by activating only ~3B of its 80B parameters per token prediction—achieving performance rivaling much larger dense models at a fraction of the cost.
Open-Source and Enterprise-Ready
Released under Apache 2.0, Qwen3-Next is freely available for both researchers and businesses, with variants fine-tuned for instructions, reasoning, and general-purpose tasks.
Key Features of Qwen3-Next
Qwen3-Next is engineered for maximum efficiency and scalability, combining cutting-edge architectural innovations with practical features that redefine what an open-source LLM can do. From sparse activation to ultra-long context, it enables faster, smarter, and more affordable AI at scale.
Hybrid Attention for Ultra-Long Contexts
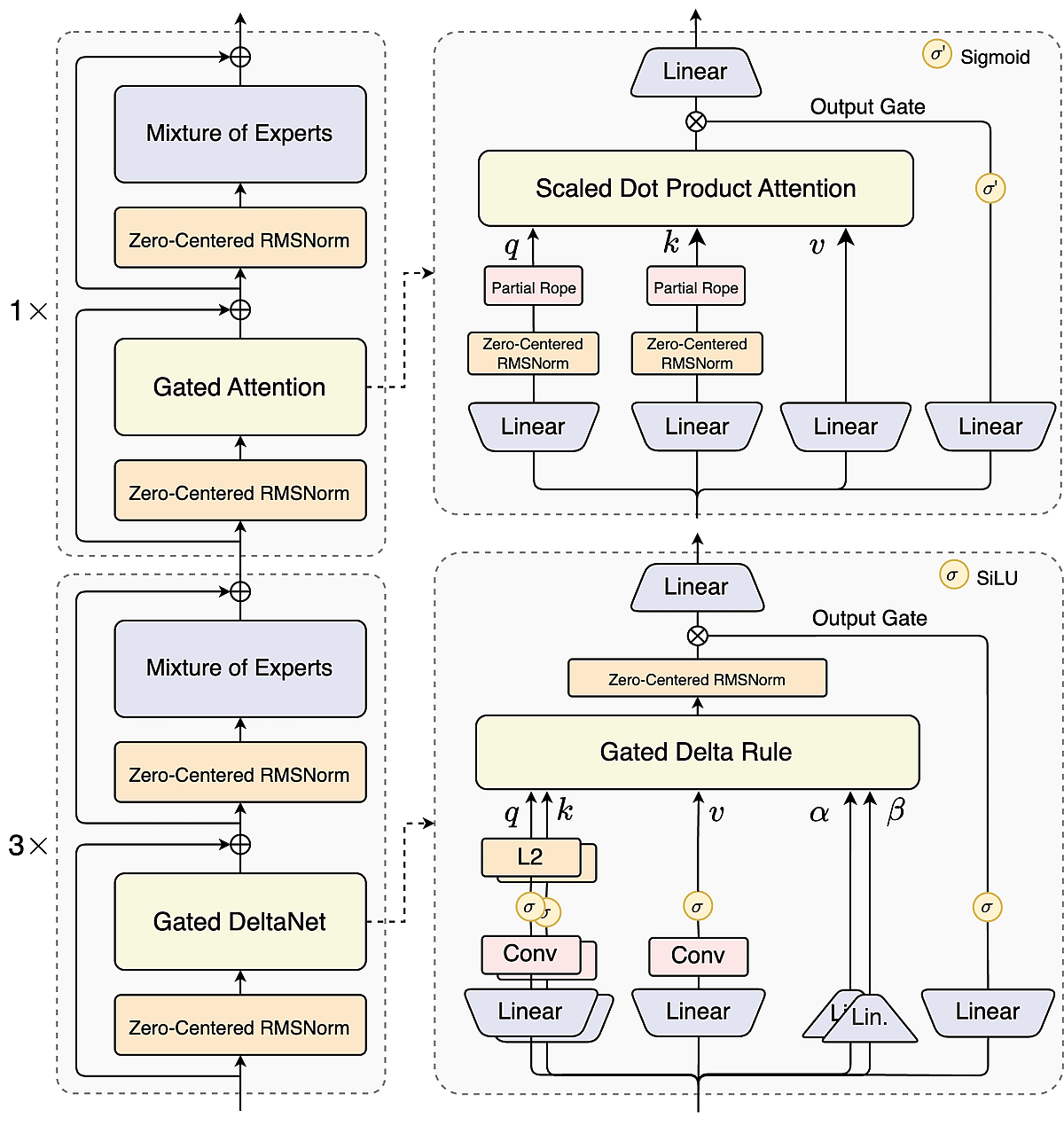
A 3:1 mix of linear-time DeltaNet and gated attention allows Qwen3-Next to handle sequences up to 262K tokens natively, balancing efficiency with accuracy for book-length documents and massive datasets.
High-Sparsity Mixture-of-Experts
With 512 experts but only 10+1 active per token, Qwen3-Next activates just 3.7% of its parameters—cutting training costs by 90% while performing like much larger dense models.
Multi-Token Prediction for Faster Output
By predicting multiple tokens per step, Qwen3-Next accelerates decoding and reduces latency, delivering smoother user experiences in chat, code generation, and long-form writing.
Agentic Tool Use & Enterprise-Ready Design
Built with tool-calling and reasoning capabilities, Qwen3-Next integrates seamlessly with APIs and workflows, making it a powerful backbone for next-gen AI agents and enterprise applications.
End-to-End Document Intelligence with Qwen3-Next
With its unprecedented context window, strong multilingual and reasoning capabilities, and open availability, it offers researchers and developers a powerful new tool. Whether you’re building an AI to sift through vast documents, a coding assistant, or just exploring the limits of language models, Qwen3-Next is an exciting platform to experiment with. As the benchmarks and user experiences have started to show, it truly competes with the best models in the world while being far more accessible in terms of cost and openness. This “efficient giant” could very well set the trend for the next wave of LLM innovation, where the goal is not just bigger – but better, faster, and smarter.

Multilingual Content & Cross-Lingual Tasks
Qwen3-Next is open-source under Apache 2.0, enabling on-prem/VPC/private-cloud deployment with your existing data stack and IAM. Use Qwen3-Next to reduce vendor lock-in, meet governance requirements, and integrate auditing/permissions for compliant enterprise workloads.

Enterprise Self-Hosting & Compliance
Qwen3-Next is open-source under Apache 2.0, enabling on-prem/VPC/private-cloud deployment with your existing data stack and IAM. Use Qwen3-Next to reduce vendor lock-in, meet governance requirements, and integrate auditing/permissions for compliant enterprise workloads.

Agent Tool Use & Automatio
Qwen3-Next includes native function calling and tool orchestration for APIs, databases, calculators, and code runners. Build multi-step agents with Qwen3-Next—retrieve → reason → compute → write → review → report—and pair with the Qwen3-Next-80B-A3B-Thinking variant for structured, step-by-step reasoning.

Long-Document Understanding
Process book-length texts, contract bundles, and multi-hour transcripts in a single pass. Qwen3-Next’s 262K context and high-sparsity MoE deliver summaries, comparisons, and deep Q&A without brittle chunking—Qwen3-Next keeps cross-references and global coherence intact.