Qwen3-Next: Alibabas Durchbruch mit 80B Parametern in Open‑Source‑KI
Erleben Sie die nächste Generation von Effizienz und Skalierung mit Qwen3-Next — Alibabas Open‑Source‑LLM mit 80B Parametern, 3B aktiv pro Inferenz und einem Rekord‑Kontextfenster von 262K. Schneller, intelligenter und für komplexe Real‑World‑Aufgaben gebaut.

Qwen3-Next: Alibabas Open‑Source‑LLM der nächsten Generation
Qwen3-Next ist Alibabas bahnbrechendes Sprachmodell mit 80B Parametern, das pro Inferenz nur 3B aktiviert und so enorme Effizienzgewinne erzielt, ohne Leistung einzubüßen. Unter Apache 2.0 open‑source gestellt, frei nutzbar für Forschung und Enterprise‑Einsatz.
Extreme Effizienz durch sparsame Aktivierung
Qwen3-Next senkt Rechenkosten, indem pro Token‑Vorhersage nur ~3B seiner 80B Parameter aktiviert werden — mit Leistung auf dem Niveau deutlich größerer dichter Modelle, aber zu einem Bruchteil der Kosten.
Open‑Source und Enterprise‑ready
Unter Apache 2.0 veröffentlicht, steht Qwen3-Next frei für Forschung und Unternehmen bereit; Varianten sind auf Instruktionen, Reasoning und allgemeine Aufgaben abgestimmt.
Wichtige Funktionen von Qwen3-Next
Qwen3-Next ist auf maximale Effizienz und Skalierbarkeit ausgelegt und verbindet modernste Architektur‑Innovationen mit praxisnahen Features, die neu definieren, was ein Open‑Source‑LLM leisten kann. Von sparsamer Aktivierung bis hin zu ultra‑langem Kontext ermöglicht es schnellere, intelligentere und günstigere KI im großen Maßstab.
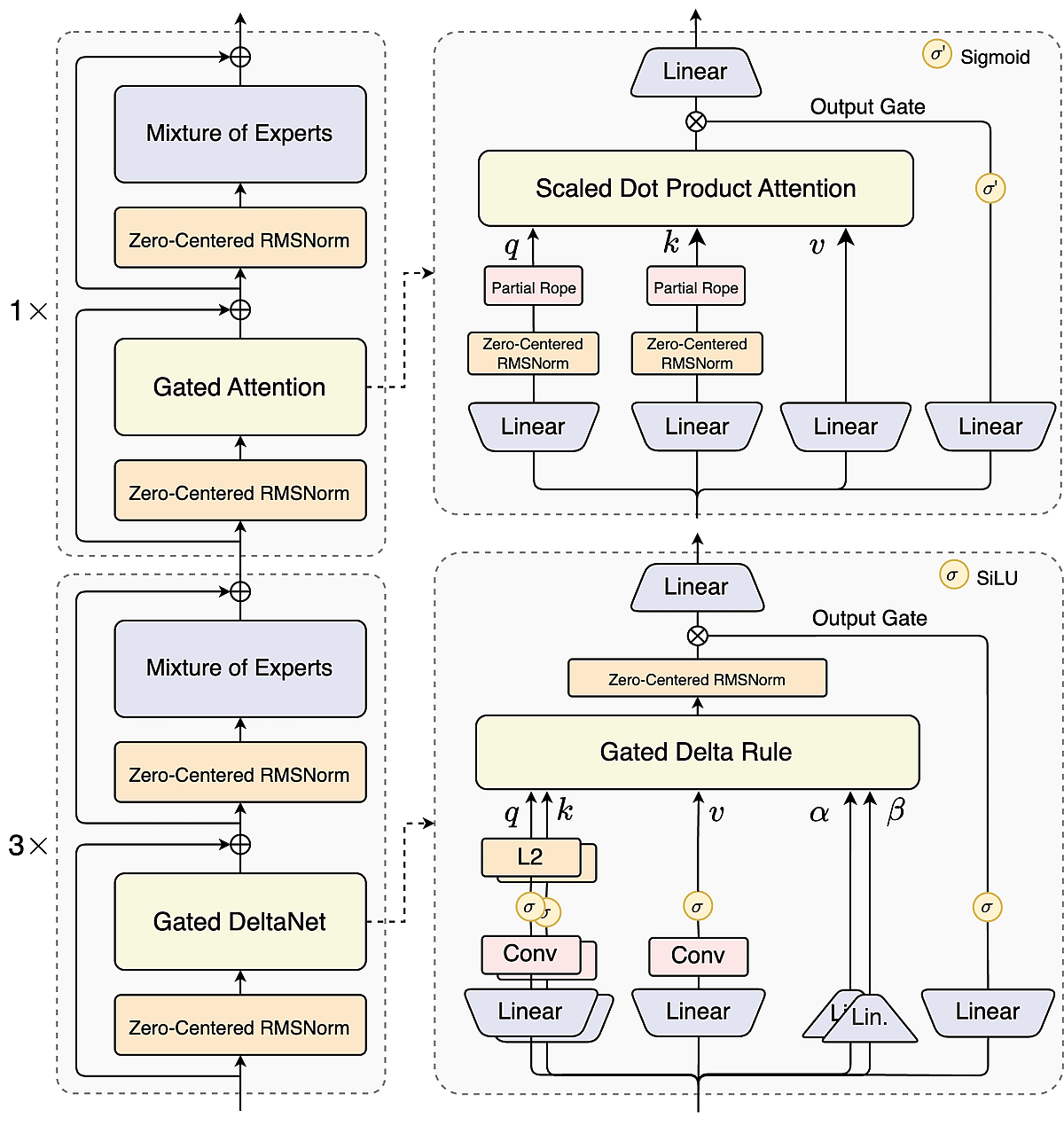
Hybrid Attention für ultra‑lange Kontexte
Ein 3:1‑Mix aus linearem DeltaNet und Gated Attention lässt Qwen3-Next Sequenzen bis zu 262K Tokens nativ verarbeiten und balanciert Effizienz mit Genauigkeit für buchlange Dokumente und riesige Datensätze.
Hoch‑sparsame Mixture‑of‑Experts
Mit 512 Experten, aber nur 10+1 aktiv pro Token, aktiviert Qwen3-Next lediglich 3,7% seiner Parameter — senkt Trainingskosten um 90% und liefert Performance wie deutlich größere dichte Modelle.
Multi‑Token‑Vorhersage für schnelleres Output
Durch Vorhersage mehrerer Tokens pro Schritt beschleunigt Qwen3-Next das Decoding und reduziert Latenz — für flüssigere Erlebnisse bei Chat, Code‑Generierung und Langtexten.
Tool‑Nutzung für Agenten & Enterprise‑Design
Mit Tool‑Aufrufen und Reasoning‑Fähigkeiten integriert sich Qwen3-Next nahtlos in APIs und Workflows und bildet das Rückgrat für Next‑Gen‑KI‑Agenten und Enterprise‑Applikationen.
End‑to‑End‑Dokumentenintelligenz mit Qwen3-Next
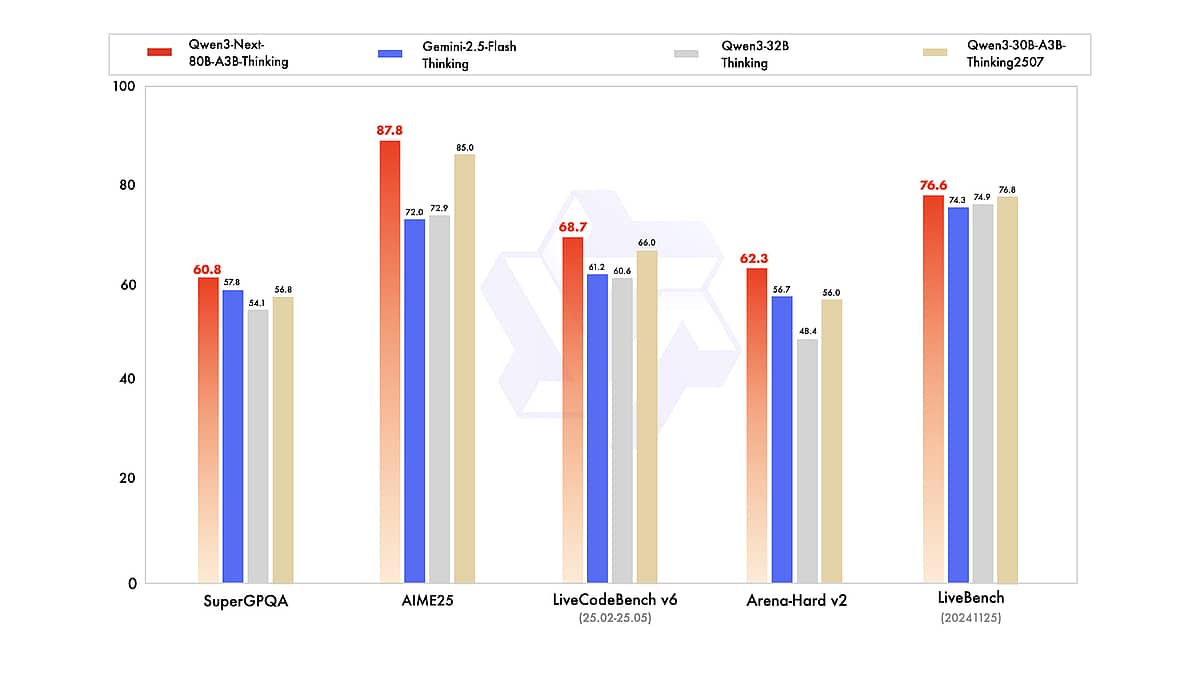
Mit seinem beispiellosen Kontextfenster, starken mehrsprachigen und Reasoning‑Fähigkeiten sowie der offenen Verfügbarkeit bietet Qwen3-Next Forschern und Entwicklern ein leistungsfähiges neues Werkzeug. Ob Sie eine KI zum Durchsuchen großer Dokumentmengen bauen, einen Coding‑Assistenten entwickeln oder die Grenzen von Sprachmodellen ausloten: Qwen3-Next ist eine spannende Plattform zum Experimentieren. Wie Benchmarks und Nutzererfahrungen bereits zeigen, konkurriert es mit den besten Modellen weltweit und ist zugleich wesentlich zugänglicher in Kosten und Offenheit. Dieser „effiziente Riese“ könnte den Trend der nächsten LLM‑Welle setzen: nicht nur größer, sondern besser, schneller und intelligenter.

Mehrsprachige Inhalte & cross‑linguale Aufgaben
Qwen3-Next ist unter Apache 2.0 open‑source und ermöglicht On‑Prem/VPC/Private‑Cloud‑Deployments mit Ihrem bestehenden Daten‑Stack und IAM. Reduzieren Sie Vendor Lock‑in, erfüllen Sie Governance‑Anforderungen und integrieren Sie Auditing/Berechtigungen für konforme Enterprise‑Workloads.

Enterprise‑Self‑Hosting & Compliance
Qwen3-Next ist unter Apache 2.0 open‑source und ermöglicht On‑Prem/VPC/Private‑Cloud‑Deployments mit Ihrem bestehenden Daten‑Stack und IAM. Nutzen Sie Qwen3-Next, um Vendor Lock‑in zu verringern, Governance zu erfüllen und Audits/Berechtigungen zu integrieren.

Agenten‑Tools & Automatisierung
Qwen3-Next bietet native Function Calling und Tool‑Orchestrierung für APIs, Datenbanken, Rechner und Code‑Runner. Bauen Sie mehrstufige Agenten — retrieve → reason → compute → write → review → report — und kombinieren Sie sie mit der Variante Qwen3-Next-80B-A3B-Thinking für strukturiertes, schrittweises Reasoning.

Verständnis langer Dokumente
Verarbeiten Sie Buch‑lange Texte, Vertragsbündel und mehrstündige Transkripte in einem Durchlauf. Das 262K‑Kontextfenster von Qwen3-Next und sein hoch‑sparsames MoE liefern Zusammenfassungen, Vergleiche und tiefgehendes Q&A ohne fragiles Chunking — Querverweise und globale Kohärenz bleiben erhalten.