Qwen3-Next : percée d’Alibaba à 80B paramètres dans l’IA open source
Découvrez la nouvelle génération d’efficacité et d’échelle avec Qwen3-Next — le LLM open source d’Alibaba doté de 80B de paramètres, 3B actifs par inférence et d’une fenêtre de contexte record de 262K. Plus rapide, plus intelligent, conçu pour des tâches réelles complexes.

Qwen3-Next : LLM open source de nouvelle génération d’Alibaba
Qwen3-Next est un modèle linguistique révolutionnaire de 80B paramètres d’Alibaba qui n’en active que 3B par inférence, offrant de grands gains d’efficacité sans sacrifier les performances. Publié sous Apache 2.0, il est librement disponible pour la recherche et le déploiement en entreprise.
Efficacité extrême grâce à l’activation clairsemée
Qwen3-Next réduit fortement les coûts de calcul en n’activant qu’environ 3B de ses 80B paramètres par prédiction de token — atteignant des performances proches de grands modèles denses à une fraction du coût.
Open source et prêt pour l’entreprise
Publié sous Apache 2.0, Qwen3-Next est librement accessible pour les chercheurs et les entreprises, avec des variantes adaptées aux instructions, au raisonnement et aux tâches générales.
Fonctionnalités clés de Qwen3-Next
Qwen3-Next est conçu pour une efficacité et une évolutivité maximales, combinant des innovations architecturales de pointe avec des capacités pratiques qui redéfinissent ce qu’un LLM open source peut faire. De l’activation clairsemée au contexte ultra‑long, il permet une IA plus rapide, plus intelligente et plus abordable à grande échelle.
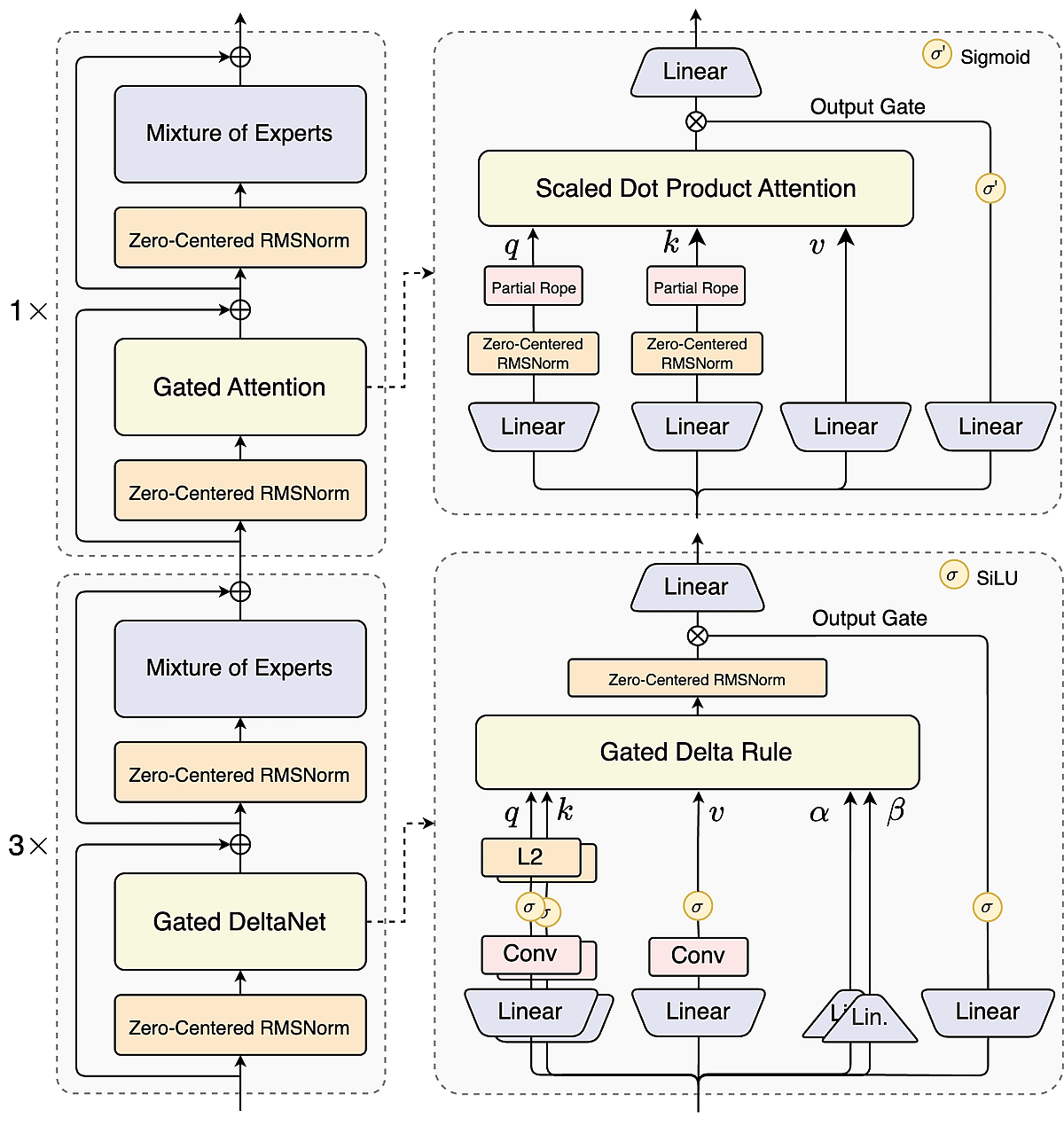
Hybrid Attention pour contextes ultra‑longs
Un mélange 3:1 de DeltaNet (linéaire) et d’attention gated permet à Qwen3-Next de gérer nativement jusqu’à 262K tokens, conciliant efficacité et précision pour des documents de la taille d’un livre et d’immenses jeux de données.
Mixture‑of‑Experts à forte parcimonie
Avec 512 experts mais seulement 10+1 actifs par token, Qwen3-Next n’active qu’environ 3,7% de ses paramètres — réduisant les coûts d’entraînement de 90% tout en rivalisant avec de grands modèles denses.
Prédiction multi‑tokens pour un débit accru
En prédisant plusieurs tokens par étape, Qwen3-Next accélère le décodage et réduit la latence, offrant une expérience plus fluide pour le chat, la génération de code et la rédaction longue.
Outils d’agent et conception prête pour l’entreprise
Doté d’appels d’outils et de capacités de raisonnement, Qwen3-Next s’intègre aux API et workflows, devenant l’épine dorsale d’agents IA nouvelle génération et d’applications d’entreprise.
Intelligence documentaire de bout en bout avec Qwen3-Next
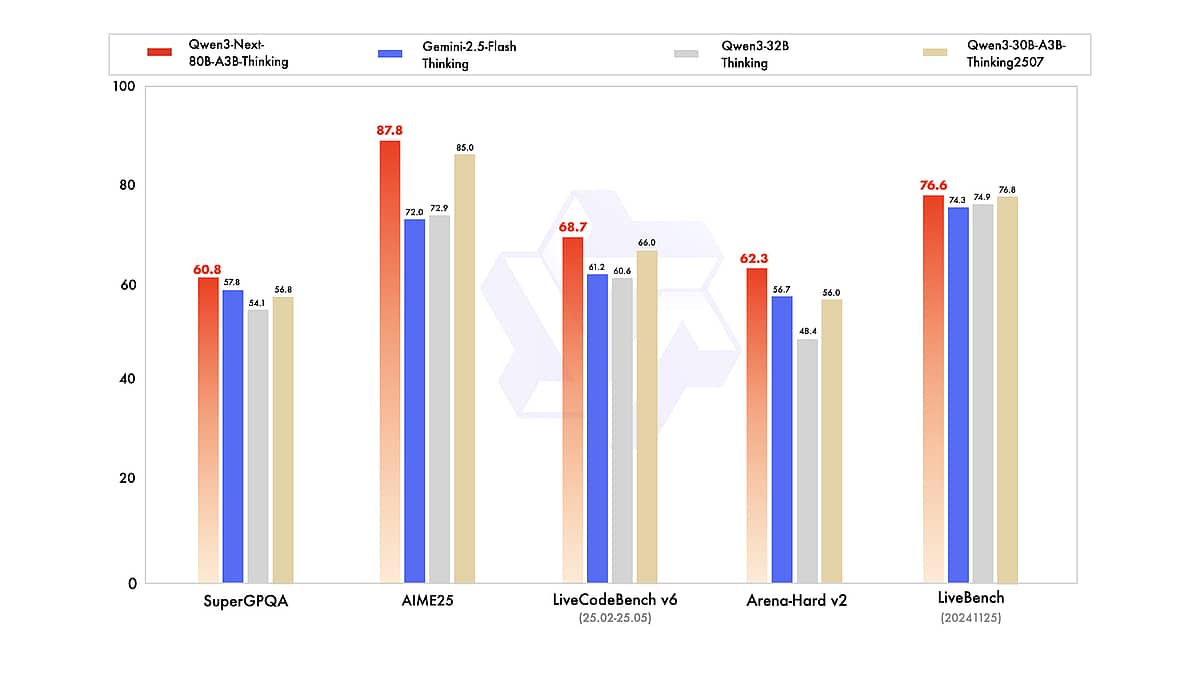
Grâce à sa fenêtre de contexte sans précédent, à ses solides capacités multilingues et de raisonnement, et à sa disponibilité ouverte, Qwen3-Next offre aux chercheurs et aux développeurs un nouvel outil puissant. Que vous construisiez une IA pour parcourir d’immenses documents, un assistant de codage, ou que vous exploriez simplement les limites des modèles de langage, Qwen3-Next est une plateforme stimulante pour l’expérimentation. Comme l’indiquent déjà les benchmarks et les retours d’usage, il rivalise véritablement avec les meilleurs modèles au monde tout en restant bien plus accessible en coût et en ouverture. Ce « géant efficace » pourrait bien définir la tendance de la prochaine vague d’innovation LLM, où l’objectif n’est pas seulement plus grand — mais meilleur, plus rapide et plus intelligent.

Contenus multilingues et tâches interlinguistiques
Qwen3-Next est open source sous Apache 2.0, permettant un déploiement on‑prem/VPC/cloud privé avec votre pile de données et IAM existantes. Réduisez la dépendance aux fournisseurs, respectez vos exigences de gouvernance et intégrez audit/autorisations pour des charges de travail conformes.

Auto‑hébergement et conformité d’entreprise
Qwen3-Next est open source sous Apache 2.0, permettant un déploiement on‑prem/VPC/cloud privé avec votre pile de données et IAM existantes. Utilisez Qwen3-Next pour réduire l’enfermement propriétaire, satisfaire aux exigences de gouvernance et intégrer audit/autorisations pour des charges de travail conformes.

Utilisation d’outils par agents et automatisation
Qwen3-Next inclut l’appel de fonctions natif et l’orchestration d’outils pour API, bases de données, calculateurs et exécutants de code. Construisez des agents multi‑étapes — retrieve → reason → compute → write → review → report — et associez‑le à la variante Qwen3-Next-80B-A3B-Thinking pour un raisonnement structuré pas à pas.

Compréhension de longs documents
Traitez des textes de longueur livre, des liasses de contrats et des transcriptions de plusieurs heures en un seul passage. La fenêtre de contexte 262K de Qwen3-Next et son MoE à forte parcimonie permettent des résumés, des comparaisons et des questions‑réponses approfondies sans découpage fragile — tout en préservant les renvois et la cohérence globale.