Qwen3-Next:阿里巴巴在开源 AI 领域的 800 亿参数突破
体验 Qwen3-Next 带来的新一代效率与可扩展性——阿里巴巴开源 LLM,拥有 800 亿参数、推理时仅激活 30 亿参数,以及创纪录的 262K 上下文窗口。更快、更聪明,专为复杂的真实世界任务而生。

Qwen3-Next:阿里巴巴的下一代开源 LLM
Qwen3-Next 是阿里巴巴开创性的 800 亿参数语言模型,推理时仅激活 30 亿参数,在不牺牲性能的前提下显著提升效率。以 Apache 2.0 开源发布,研究与企业部署均可自由使用。
稀疏激活带来极致效率
Qwen3-Next 在每次 token 预测时仅激活约 30 亿个参数(总计 800 亿),以远低于成本的方式实现可与更大密集模型媲美的性能。
开源且面向企业
在 Apache 2.0 许可下发布,Qwen3-Next 面向研究与企业自由可用,并提供针对指令、推理与通用任务优化的多种变体。
Qwen3-Next 的关键特性
Qwen3-Next 以极致效率与可扩展性为目标,将前沿的架构创新与实用能力相结合,重塑开源 LLM 的能力边界。从稀疏激活到超长上下文,让大规模 AI 更快、更聪明、更经济。
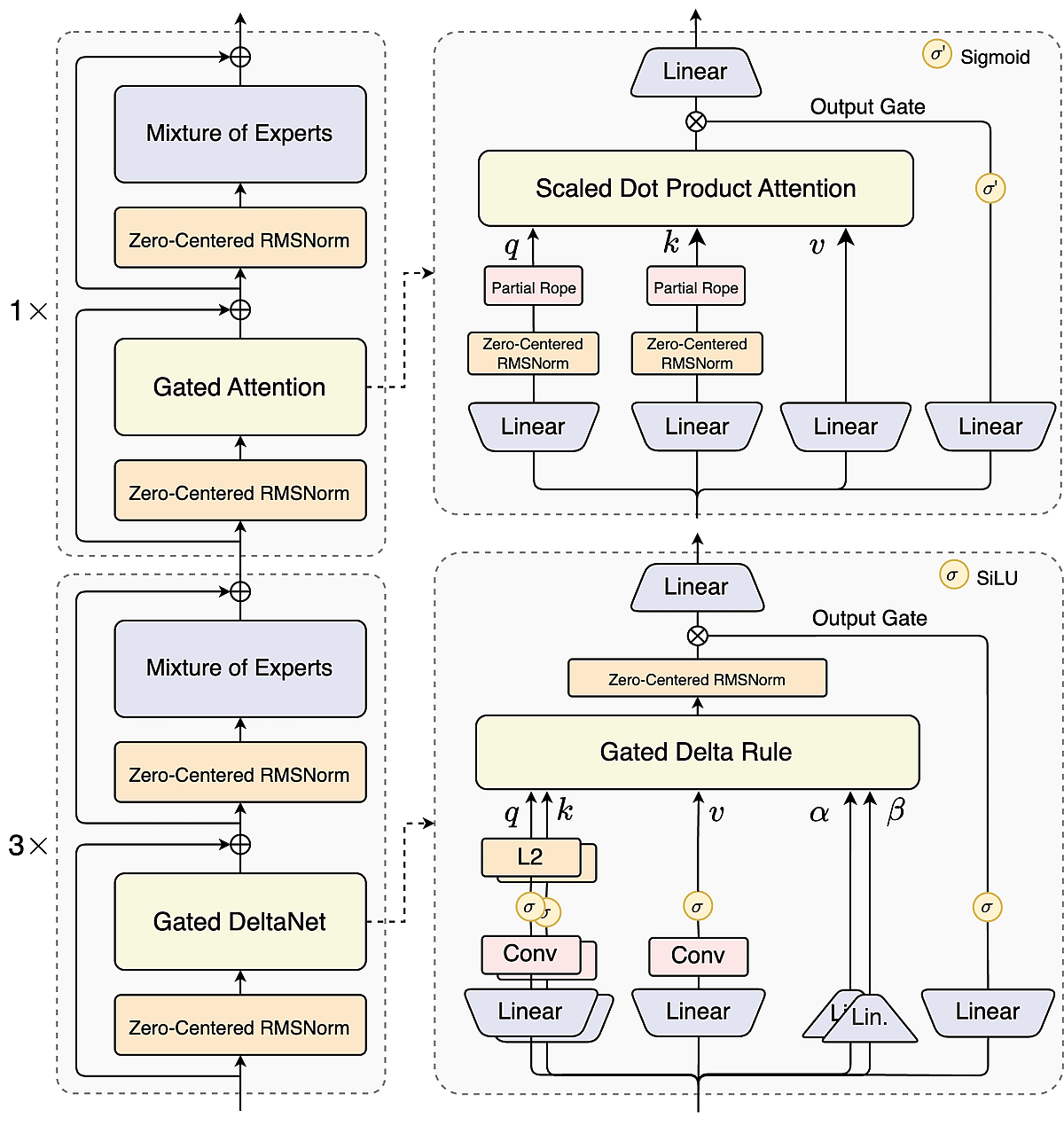
面向超长上下文的 Hybrid Attention
线性时间的 DeltaNet 与门控注意力按 3:1 融合,使 Qwen3-Next 可原生处理最长 262K 的序列,在效率与准确性之间取得平衡,适用于书籍级文档与海量数据。
高稀疏度的专家混合(MoE)
拥有 512 个专家,但每个 token 仅激活 10+1 个,Qwen3-Next 仅激活约 3.7% 的参数——在保持大模型表现的同时将训练成本降低约 90%。
多 Token 预测,加速生成
通过每步预测多个 token,Qwen3-Next 提升解码速度、降低时延,为聊天、代码生成与长文写作带来更顺滑的体验。
面向代理的工具使用与企业级设计
内建工具调用与推理能力,Qwen3-Next 可无缝对接 API 与工作流,成为新一代 AI 代理与企业应用的强大底座。
基于 Qwen3-Next 的端到端文档智能
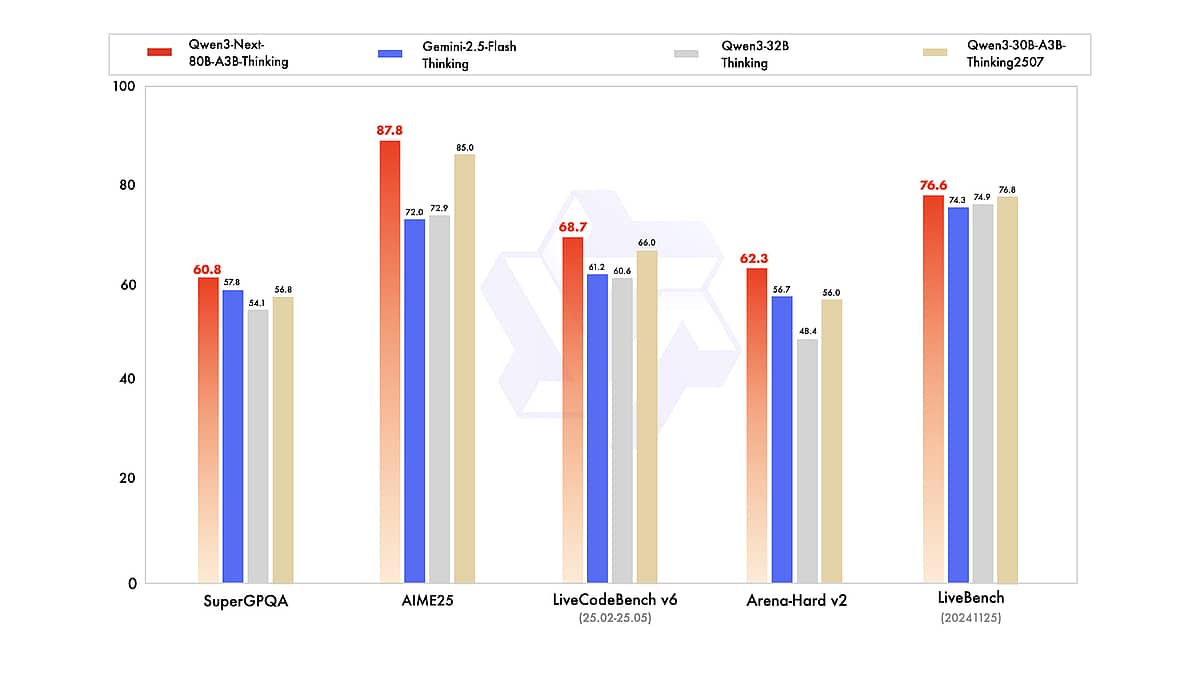
凭借前所未有的上下文窗口、强大的多语言与推理能力以及开放可用性,Qwen3-Next 为研究者与开发者提供了强大的新工具。无论是构建用于筛选海量文档的 AI、打造编码助手,还是探索语言模型的能力边界,Qwen3-Next 都是极具潜力的实验平台。正如基准评测与用户体验所展现的那样,它与当今最强模型不相上下,同时在成本与开放性方面更具可及性。这个“高效巨人”很可能引领下一波 LLM 创新趋势——目标不只是更大,而是更好、更快、更聪明。

多语言内容与跨语种任务
Qwen3-Next 以 Apache 2.0 开源发布,可结合现有数据栈与 IAM 在本地/VPC/私有云中部署。借助 Qwen3-Next 减少厂商锁定,满足合规治理需求,并集成审计/权限以支撑企业级工作负载。

企业自托管与合规
Qwen3-Next 以 Apache 2.0 开源发布,可在本地/VPC/私有云部署并对接既有的数据与身份体系。通过 Qwen3-Next 降低供应商锁定风险,满足治理要求,并可集成审计/权限以实现合规。

代理工具使用与自动化
Qwen3-Next 原生支持函数调用与工具编排,覆盖 API、数据库、计算器与代码运行器。可构建多步骤代理流程(retrieve → reason → compute → write → review → report),并结合 Qwen3-Next-80B-A3B-Thinking 变体实现结构化的逐步推理。

长文档理解
在一次推理中处理书籍级文本、合同组卷与数小时转录。Qwen3-Next 的 262K 上下文与高稀疏 MoE 支持摘要、对比与深度问答,而无需脆弱的分块,并能保持跨段引用与全局一致性。